Stream.FM
Real-Time Streamable Generative Speech Restoration with Flow Matching
 arXiv preprint
arXiv preprint Code and Checkpoints (coming soon)
Code and Checkpoints (coming soon)
⤵️ Jump to Results for:
Stream.FM : Real-Time Streamable Generative Speech Restoration with Flow Matching
Simon Welker, Bunlong Lay, Maris Hillemann, Tal Peer, Timo Gerkmann
Abstract
Diffusion-based generative models have greatly impacted the speech processing field in recent years, exhibiting high speech naturalness and spawning a new research direction. Their application in real-time communication is, however, still lagging behind due to their computation-heavy nature involving multiple calls of large DNNs.
Here, we present Stream.FM , a frame-causal flow-based generative model with an algorithmic latency of 32 milliseconds (ms) and a total latency of 48 ms, paving the way for generative speech processing in real-time communication. We propose a buffered streaming inference scheme and an optimized DNN architecture, show how learned few-step numerical solvers can boost output quality at a fixed compute budget, explore model weight compression to find favorable points along a compute/quality tradeoff, and contribute a model variant with 24 ms total latency for the speech enhancement task.
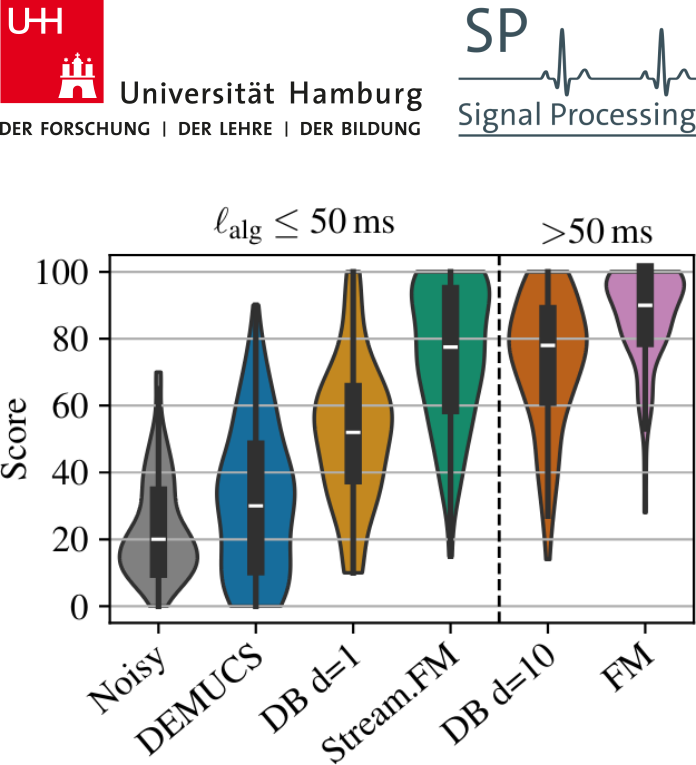
Our work looks beyond theoretical latencies, showing that high-quality streaming generative speech processing can be realized on consumer GPUs available today. Stream.FM can solve a variety of speech processing tasks in a streaming fashion: speech enhancement, dereverberation, codec post-filtering, bandwidth extension, STFT phase retrieval, and Mel vocoding. As we verify through comprehensive evaluations and a MUSHRA listening test, Stream.FM establishes a state-of-the-art for generative streaming speech restoration, exhibits only a reasonable reduction in quality compared to a non-streaming variant, and outperforms our recent work (Diffusion Buffer ) on generative streaming speech enhancement while operating at a lower latency.
Speech Enhancement
Select an audio file:
Clean:
Noisy:
Stream.FM (4xEuler):
Stream.FM (LRK4):
Stream.FM (LRK4-PESQ):
Stream.FM (1xEuler):
Stream.FM Initial Predictor:
Diffusion Buffer (d=0):
Diffusion Buffer (d=9):
Causal SEMamba :
DeepFilterNet3 :
DEMUCS :
CleanUMamba :
HiFi-Stream :
FM (4xEuler):
SBVE :
AnyEnhance :
aTENNuate :
MambAttention :
Dereverberation
Select an audio file:
Clean:
Reverberant:
Stream.FM (5xEuler):
Stream.FM (LRK5):
Stream.FM (LRK5-PESQ):
Stream.FM (1xEuler):
FM (5xEuler):
SGMSE+ (48 kHz):
AnyEnhance (44.1 kHz):
Codec Postfiltering (Lyra V2)
Select an audio file:
Clean:
Lyra V2 Decoder:
Stream.FM (5xEuler):
Stream.FM (LRK5):
Stream.FM (LRK5-PESQ):
Stream.FM (1xEuler):
FM (5xEuler):
AnyEnhance (16 kHz):
Bandwidth Extension
Select an audio file:
Clean:
Downsampled:
Stream.FM (5xEuler):
Stream.FM (LRK5):
Stream.FM (LRK5-PESQ):
Stream.FM (1xEuler):
FM (5xEuler):
AnyEnhance (44.1 kHz):
STFT Phase Retrieval
Select an audio file:
Clean:
Zero-phase:
Stream.FM (5xEuler):
Stream.FM (LRK5):
Stream.FM (1xEuler):
RTISI-DM :
FM (5xEuler):
DiffPhase :
Mel Vocoding
Select an audio file:
Clean:
Pseudoinverse + Zero-phase:
Pseudoinverse + RTISI-DM :
Stream.FM (5xEuler):
Stream.FM (LRK5):
Stream.FM (1xEuler):
FM (5xEuler):
HiFi-GAN (16 kHz):
Citation
If you use our models, methods, or any derivatives thereof, please cite our research paper:
@article{
welker2025streamfm,
title={Real-Time Streamable Generative Speech Restoration with Flow Matching},
author={Simon Welker and Bunlong Lay and Maris Hillemann and Tal Peer and Timo Gerkmann},
year={2025},
journal={arXiv preprint arXiv:2512.19442},
doi={10.48550/arXiv.2512.19442}
}